分页: 1 / 1
#1 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 14日 13:12
由 TheMatrix
#2 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 14日 16:07
由 Caravel
之前看到lecun的报告说,
next token这种办法对图像效果不行
因为图像像素是连续变量,不像token是离散的
#3 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 14日 16:29
由 TheMatrix
Caravel 写了: 2025年 1月 14日 16:07
之前看到lecun的报告说,
next token这种办法对图像效果不行
因为图像像素是连续变量,不像token是离散的
肯定不能用像素做token。
#4 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 14日 16:36
由 赖美豪中
自信一点对复杂得语义也不行
Caravel 写了: 2025年 1月 14日 16:07
之前看到lecun的报告说,
next token这种办法对图像效果不行
因为图像像素是连续变量,不像token是离散的
#5 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 15日 14:17
由 TheMatrix
看了一下。是一个review,没有什么有启发的东西。
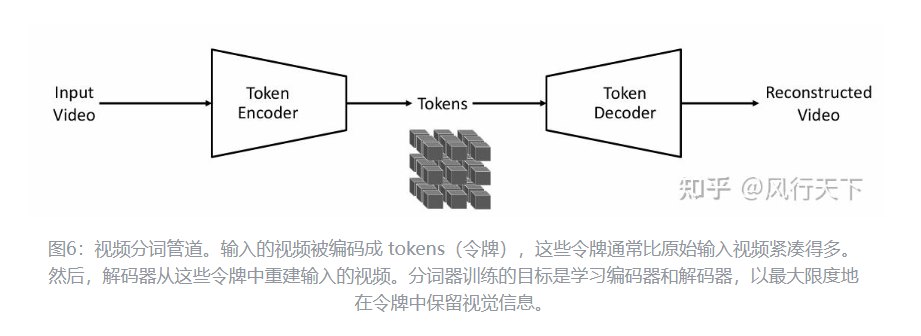
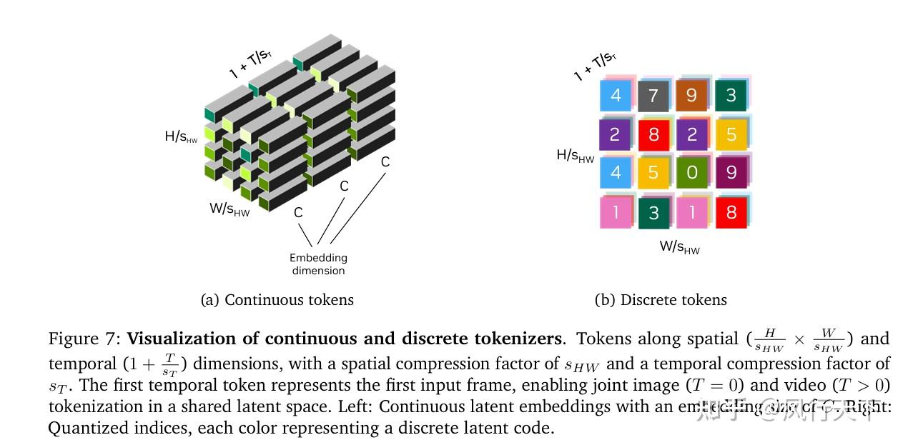
我主要关心tokenization,image或者video的tokenization,输入方面的。
它里面介绍的两种,无论discrete还是continuous tokenization,都没有看到我想要看到的东西:
viewtopic.php?p=4812354#p4812354
#6 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 15日 14:59
由 Caravel
目前这种用LLM方法搞出的多模态不行,要从机器人那里bottom up 世界模型
#7 Re: 这个题目很重要 - 多模态 next token prediction
发表于 : 2025年 1月 19日 09:32
由 TheMatrix