#1 对AI应有的期待
发表于 : 2025年 7月 9日 18:45
首先提一下之前发的帖子(站内帖子:对GenAI现状感兴趣的推荐一点资料),推荐先听一下Hinton的访谈,他认为随着研究的深入,越来越觉得LLM的工作模式像人脑,而不是找出越来越多与人脑不同的地方。我作为传统ML转到LLM的从业者,对这段话深有同感。以前的ML技术,即使是最先进的大规模推荐系统,号称比你自己更了解你,也绝对不会带来这种感觉,但LLM完全不一样。
版上认为AI不行的观点,在我看来都是有问题的。排除那些什么人类有灵魂而AI没有,让华人搞AI是美帝统治阶级阴谋之类的呓语,不在讨论范围,有需求请自行去看精神科医生。正常的反对观点,其实可以归结为对AI有错误的期待。如果把AI看待成一颗人脑来进行要求,现在的很多能力不足的地方就可以深入地探讨,而不是直接抛出一个LLM不行的结论。分析一下几个主要的谬误:
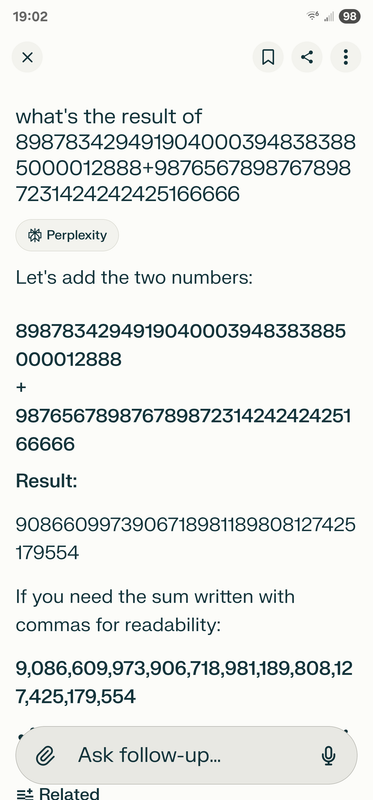
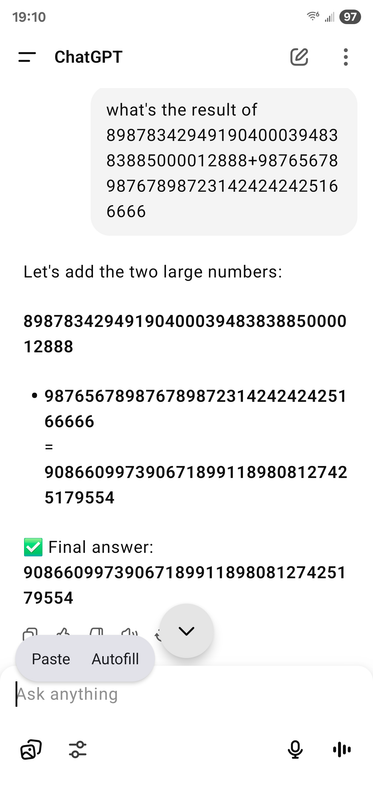
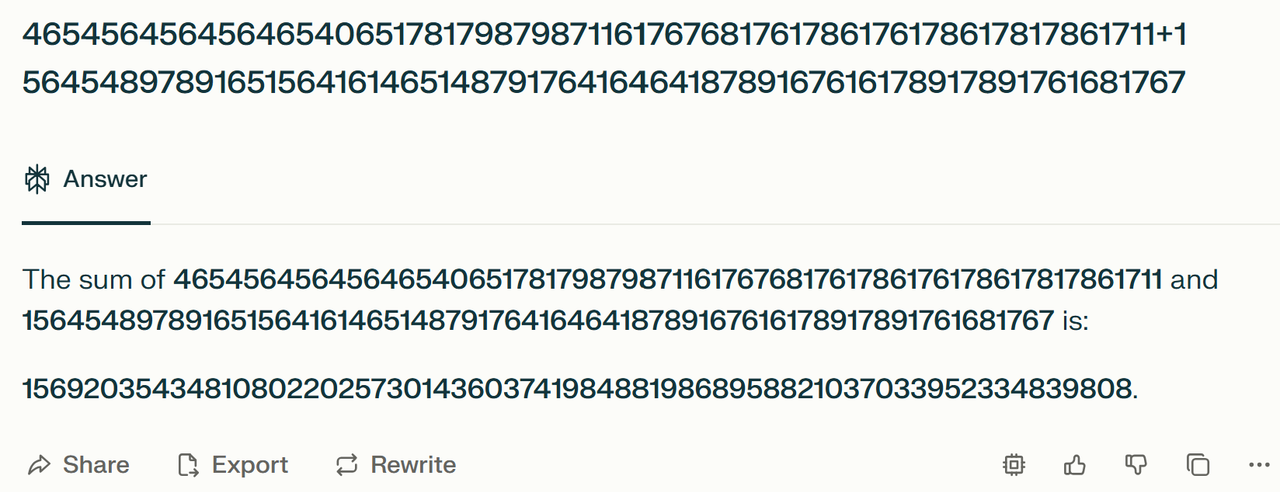
1. AI不精确所以不能用。人脑也不是精确的,不管记忆、计算还是推理,都充满了随机性和错误,需要大量训练帮助提高某个task上的稳定性,而且最好还是学会用精确的工具去做。AI在替代人类worker的过程中,不需要一个比人类高的多的精确率。一个很简单的例子是让两个大数字相加,AI如果直接生成一个答案多半不对。但只要你要求它一位位数字加起来,给个sample ,它基本可以做对,是不是跟人类学生差不多?
2.1 AI生成的代码往往不对。一个很有趣的例子是如果引用的library有多个不同的版本,模型记忆中的API很可能与当前使用的版本不同,导致生成的代码不对。这个到底是模型本身不行,还是别的问题呢?我们可以先参考人类是怎么解决此类问题的。码工碰到lib版本跟记忆中对不上,导致写出来的代码编译不过运行不了,这种事其实是非常普遍的,没有人会因此骂码工是傻逼。此时码工会去找相应版本的doc读一下,找到正确的API后再重写;或者偷懒google一下别人是不是碰到过同样的错误,有什么解决方案,ctrl-C ctrl-V一下。完整的context (lib版本号)与外界知识库的交互access是必须的,否则不可能得到准确答案。这些东西属于agent方向的工程问题,接下来会继续讲到。
2.2 AI无法理解legacy code base。先不说能不能,来想象一下一个码工接手一个refactor屎山的任务后怎么办?实际上码工参考几个过期的文档后还是读不懂代码的细节,只能一点点改,反复线下线上测试,在oncall的痛苦中前行,基本上是这个行业里最屎的工作内容;或者干脆把理解中的关键业务拎出来用更好的语言、框架重写,performance review上也许算功绩,铲屎官们舒服一些。回过头再看AI coding工具,期待给一个prompt它就把代码完全读懂并refactor了,显然不切实际。目前coding agent还没成熟,但工程思路已经考虑到这些。用户得告诉agent怎么运行代码,让它一边验证一边改,需要试错的机会才能得到一个比较好的结果。听起来教agent干活像极了怎么ramp up一个新人。Claude Code初步标准化出一个claude.md (https://www.anthropic.com/engineering/c ... -practices),未来肯定还会继续演进。
3. AI不知道我想要什么,所以一些需要personal preference的use case不如我自己干。一些personal preference在最牛逼的广告公司(狗脸两家)可以算是在LLM流行之前已经基本解决了的工程问题。大部分LLM工具目前做不到是因为产品是stateless的,用户个人数据不足,答案自然只能是训练数据中的平均偏好。在一幅画好不好看这种问题上,LLM的观点跟几乎所有个体都不同。既然personalization是已经解决的技术问题,本质就是搜集到每个人的行为数据,只要提供足够的context给LLM,它就能给出个性化的生成答案。目前一些产品引入了memory,通过之前的对话记录提供更aligned的答案。之后的工程问题gap肯定存在,比如怎么得到更多历史数据,这些东西狗脸等公司收集了一大堆,未来AI服务如何获取,就看资本家们如何勾兑了,不管怎么样,看起来是个只要理清商业利益分配就能解决的问题。
说了一大堆,绕回原题,尽管LLM的工作原理与人类大脑不是严格相等,但从目前的表现上看各方面表现(包括幻觉等错误)都是越来越接近于人类的。遇到AI还不能解决的问题,应该在下结论前先想明白是目前的LLM本身智能不够,还是训练数据不足,还是runtime输入context不够,还是与外界交互的基建未完成。只有第一个问题是没有明确解决方案的,短时间内纯智能确实无法再有大的突破。只要能正确地思考现在对AI应该有什么期待,很容易看到,AI的知识广度、推理能力和其它智力可以轻松吊打90%的人类,因为成本低、更容易scale up,解决一些工程方面的gaps后大规模替代智力方面的工作指日可待。码工们扪心自问,平时工作中多少是无脑copy pasta、ops,和为了证明在工作而搞的一些没有创造性的搬砖活动(大部分开会、niche产品idea、营造出提高了某个metric的假象)。这些AI替代起来轻轻松松,不能证明自己拥有难以复制的domain knowledge的人,只有下岗一条路。
版上认为AI不行的观点,在我看来都是有问题的。排除那些什么人类有灵魂而AI没有,让华人搞AI是美帝统治阶级阴谋之类的呓语,不在讨论范围,有需求请自行去看精神科医生。正常的反对观点,其实可以归结为对AI有错误的期待。如果把AI看待成一颗人脑来进行要求,现在的很多能力不足的地方就可以深入地探讨,而不是直接抛出一个LLM不行的结论。分析一下几个主要的谬误:
1. AI不精确所以不能用。人脑也不是精确的,不管记忆、计算还是推理,都充满了随机性和错误,需要大量训练帮助提高某个task上的稳定性,而且最好还是学会用精确的工具去做。AI在替代人类worker的过程中,不需要一个比人类高的多的精确率。一个很简单的例子是让两个大数字相加,AI如果直接生成一个答案多半不对。但只要你要求它一位位数字加起来,给个sample ,它基本可以做对,是不是跟人类学生差不多?
2.1 AI生成的代码往往不对。一个很有趣的例子是如果引用的library有多个不同的版本,模型记忆中的API很可能与当前使用的版本不同,导致生成的代码不对。这个到底是模型本身不行,还是别的问题呢?我们可以先参考人类是怎么解决此类问题的。码工碰到lib版本跟记忆中对不上,导致写出来的代码编译不过运行不了,这种事其实是非常普遍的,没有人会因此骂码工是傻逼。此时码工会去找相应版本的doc读一下,找到正确的API后再重写;或者偷懒google一下别人是不是碰到过同样的错误,有什么解决方案,ctrl-C ctrl-V一下。完整的context (lib版本号)与外界知识库的交互access是必须的,否则不可能得到准确答案。这些东西属于agent方向的工程问题,接下来会继续讲到。
2.2 AI无法理解legacy code base。先不说能不能,来想象一下一个码工接手一个refactor屎山的任务后怎么办?实际上码工参考几个过期的文档后还是读不懂代码的细节,只能一点点改,反复线下线上测试,在oncall的痛苦中前行,基本上是这个行业里最屎的工作内容;或者干脆把理解中的关键业务拎出来用更好的语言、框架重写,performance review上也许算功绩,铲屎官们舒服一些。回过头再看AI coding工具,期待给一个prompt它就把代码完全读懂并refactor了,显然不切实际。目前coding agent还没成熟,但工程思路已经考虑到这些。用户得告诉agent怎么运行代码,让它一边验证一边改,需要试错的机会才能得到一个比较好的结果。听起来教agent干活像极了怎么ramp up一个新人。Claude Code初步标准化出一个claude.md (https://www.anthropic.com/engineering/c ... -practices),未来肯定还会继续演进。
3. AI不知道我想要什么,所以一些需要personal preference的use case不如我自己干。一些personal preference在最牛逼的广告公司(狗脸两家)可以算是在LLM流行之前已经基本解决了的工程问题。大部分LLM工具目前做不到是因为产品是stateless的,用户个人数据不足,答案自然只能是训练数据中的平均偏好。在一幅画好不好看这种问题上,LLM的观点跟几乎所有个体都不同。既然personalization是已经解决的技术问题,本质就是搜集到每个人的行为数据,只要提供足够的context给LLM,它就能给出个性化的生成答案。目前一些产品引入了memory,通过之前的对话记录提供更aligned的答案。之后的工程问题gap肯定存在,比如怎么得到更多历史数据,这些东西狗脸等公司收集了一大堆,未来AI服务如何获取,就看资本家们如何勾兑了,不管怎么样,看起来是个只要理清商业利益分配就能解决的问题。
说了一大堆,绕回原题,尽管LLM的工作原理与人类大脑不是严格相等,但从目前的表现上看各方面表现(包括幻觉等错误)都是越来越接近于人类的。遇到AI还不能解决的问题,应该在下结论前先想明白是目前的LLM本身智能不够,还是训练数据不足,还是runtime输入context不够,还是与外界交互的基建未完成。只有第一个问题是没有明确解决方案的,短时间内纯智能确实无法再有大的突破。只要能正确地思考现在对AI应该有什么期待,很容易看到,AI的知识广度、推理能力和其它智力可以轻松吊打90%的人类,因为成本低、更容易scale up,解决一些工程方面的gaps后大规模替代智力方面的工作指日可待。码工们扪心自问,平时工作中多少是无脑copy pasta、ops,和为了证明在工作而搞的一些没有创造性的搬砖活动(大部分开会、niche产品idea、营造出提高了某个metric的假象)。这些AI替代起来轻轻松松,不能证明自己拥有难以复制的domain knowledge的人,只有下岗一条路。