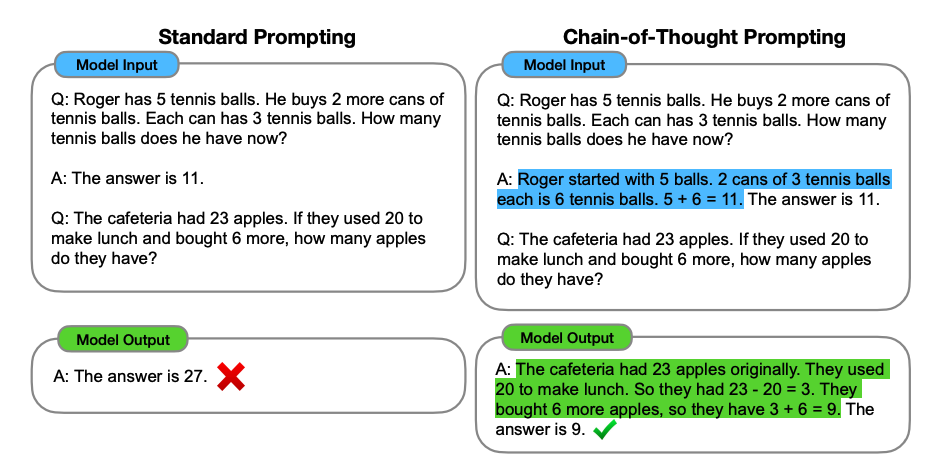
其实语言模型的evaluation一直是难点,包括以前早期模型。xiaoju 写了: 2023年 12月 19日 19:06 貌似ChatGPT的API里没有还没有准确率这个选项吧,比如如何设定不知道就说不知道,千万不要胡说,内容的准确性非常重要请尽一切可能交叉校对这个需求
如果有参照文本,那些传统metrics比如BLEU, ROUGE还是可以用,但会低估模型的水平。现在也有专门针对大模型的评估办法,有各种利弊。
有些特定任务,比如从文本里抓取一些entity,评估比较简单
版主: Softfist
其实语言模型的evaluation一直是难点,包括以前早期模型。xiaoju 写了: 2023年 12月 19日 19:06 貌似ChatGPT的API里没有还没有准确率这个选项吧,比如如何设定不知道就说不知道,千万不要胡说,内容的准确性非常重要请尽一切可能交叉校对这个需求
非也。

天下程序一大抄,大概率ChatGPT见过类似的程序nohup 写了: 2023年 12月 19日 21:07 看一个系统具有什么样的智能,有很多测试的基准。其中很重要的一条就是归纳。
一个机器能归纳,毫无疑问,应该具有相当高的智能了。
你可以试试问问chatGPT: I have a sequence of numbers like 3, 5, 8, 13, 21, .... can you induct what this sequence is?
试试各种隐含规律的数列,看看chatGPT的回答 (直接给出通项公式),不得不承认这个语言模型是有智能的。起码很多人都未必能找到规律。
现在我写程序,经常会让chatGPT帮我写,给几个特殊情况,然后说其他类似情况都要能处理,chatGPT直接输出算法,把一般情况都解决了。它能从你说的特殊情况,总结出一般情况。比很多人聪明太多了。
大语言模型已经比你聪明了,你还在这夸夸其谈。Caravel 写了: 2023年 12月 19日 14:14 大语言模型到底是语言的model,还是智能的model,我怀疑是前者。
真正的人工智能,需要的input很少,一个小孩学到大学,读的书,跟人说的话,可能不到现在LLM训练材料的万分之一。人工智能的体现在于输入很少,输出很多,LLM是输入很多,输出很多。
我把一个我的初稿扔给你润色,你能做到多好?
LLM很容易纠错,这叫精调模型。
shot 写了: 2023年 12月 19日 21:51 这是交流成本,正说明大语言模型是一种智能。
实际上,人和人之间的交流成本是极高的。
这是高级智能一个本质特征,每个人的神经网络参数都是不一样的。
这导致大家对相同事物的理解和猜测各不一样。
在大语言模型上,花的这点成本,跟人的交流成本比,小意思了。