#141 Re: 完了,deepseek把GPU上的fp8的汇编代码开源了。
发表于 : 2025年 2月 26日 17:27
上H200啊。既想要精度又想要规模,那就只能多烧钱,世上哪有那么多便宜的事。
上H200啊。既想要精度又想要规模,那就只能多烧钱,世上哪有那么多便宜的事。
不属实
嗯,你有个GPU说明书,就等于有GPU了,连PPT都可以省了
芯片和计算机是一回事吗?不懂就别来现眼了
华为升腾GPU team可以
用不着华为。N家GPU core芯片源代码国内就有,造不了。
弱智这就破防跳脚了?
無知的外行,好像寫個匯編,SASS和x86的ISA就被突破了一樣,你們連GPU到底如何運行的都不知道吧?
drifter 写了: 2025年 2月 26日 00:58 Xai的解读
DeepSeek's FP8 GEMM (General Matrix Multiplication) implementation, as showcased in their DeepGEMM library, has sparked some buzz for its reported performance, particularly when compared to NVIDIA's native APIs like cuBLAS. Based on what’s out there, here’s my take.
DeepGEMM is designed to squeeze every ounce of efficiency out of NVIDIA’s Hopper GPUs (like the H800), hitting over 1350 TFLOPS in FP8 precision under ideal conditions. That’s impressive when you consider NVIDIA’s cuBLAS, a go-to for matrix operations, is estimated to deliver around 1500 TFLOPS on an H800 for certain matrix sizes—though this scales up to 3000 TFLOPS on an H100, which DeepSeek likely didn’t use due to export restrictions. Posts on X and details from DeepSeek’s own releases suggest their library can outperform “expert-tuned kernels” (which could imply cuBLAS or similar) across a range of matrix sizes, sometimes by a significant margin—think up to 2.7x faster in extreme cases, as one X user noted.
What’s the trick? DeepGEMM uses a lightweight, just-in-time (JIT) compilation approach, keeping the core logic lean at around 300 lines of code. It leans hard into fine-grained scaling and custom optimizations, like two-level accumulation (using Tensor Cores for FP8 math and CUDA cores for higher-precision summing), to dodge the precision pitfalls of FP8. NVIDIA’s native APIs, while robust and general-purpose, don’t seem to match this level of specialization. DeepSeek’s focus on Mixture-of-Experts (MoE) layouts and their ability to tweak low-level instructions (even dabbling in PTX assembly) likely gives them an edge in tailored workloads—think AI training and inference for models like V3 and R1.
That said, it’s not a slam dunk. NVIDIA’s APIs are built for broad compatibility and reliability across diverse use cases, not just AI-specific GEMMs. DeepGEMM’s gains might shine brightest in DeepSeek’s own sandbox—optimized for their models and hardware constraints (like the H800’s nerfed bandwidth). Without head-to-head benchmarks on identical setups, claims of it being “much faster” feel anecdotal. The 1350+ TFLOPS figure is stellar, but cuBLAS could still edge out in raw peak performance on bigger matrices or less-specialized tasks. Plus, DeepSeek’s reliance on Hopper-specific Tensor Cores means it’s not a universal drop-in replacement.
So, is it “much faster”? Probably yes for DeepSeek’s niche—AI-driven, FP8-heavy, MoE-focused workloads on constrained hardware. For the average user leaning on NVIDIA’s stack? Maybe not as dramatic. It’s a testament to clever engineering over brute force, but the jury’s still out until someone runs the numbers side-by-side. What do you think—seen any solid comparisons?
过去做过很多的适配接口,不是你丫讲得那么神秘
政府禁运高端芯片禁了个寂寞。
紅藍廠都要放棄了,還沒有搞不定的,你做過GPU麼?
GPU的ISA不公開,隔幾代ISA就大變樣,而且每代都有變化,firmware永遠不公開,脫離driver你什麼都做不了,即使driver開源了,裡面還有大量的binary blob,你不知道是什麼,總之,GPU根本就無法直接操作,需要UMD、KMD、firmware間接操作。你怎麼適配?
你说的是第三家去适配nvmagagop 写了: 2025年 2月 27日 02:09 GPU的ISA不公開,隔幾代ISA就大變樣,而且每代都有變化,firmware永遠不公開,脫離driver你什麼都做不了,即使driver開源了,裡面還有大量的binary blob,你不知道是什麼,總之,GPU根本就無法直接操作,需要UMD、KMD、firmware間接操作。你怎麼適配?
華為芯片就不應該叫GPU,只能叫加速器,昇腾有Graphics能力嗎?
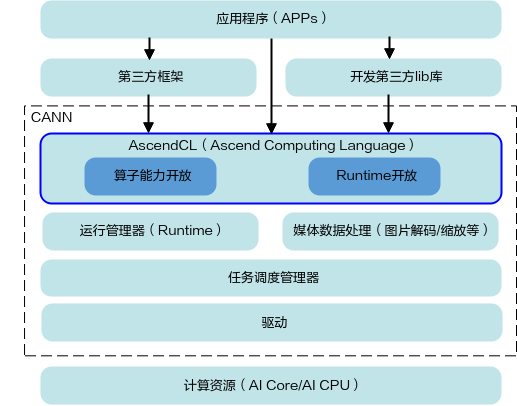
什么叫graphic 能力?有memory就能处理graphicmagagop 写了: 2025年 2月 27日 02:53 華為芯片就不應該叫GPU,只能叫加速器,昇腾有Graphics能力嗎?
華為加速器如果只支持DeepSeek,除了中國人,不會有其他客戶的,關起門來自己玩當然怎麼做都可以,下場就是龍芯。