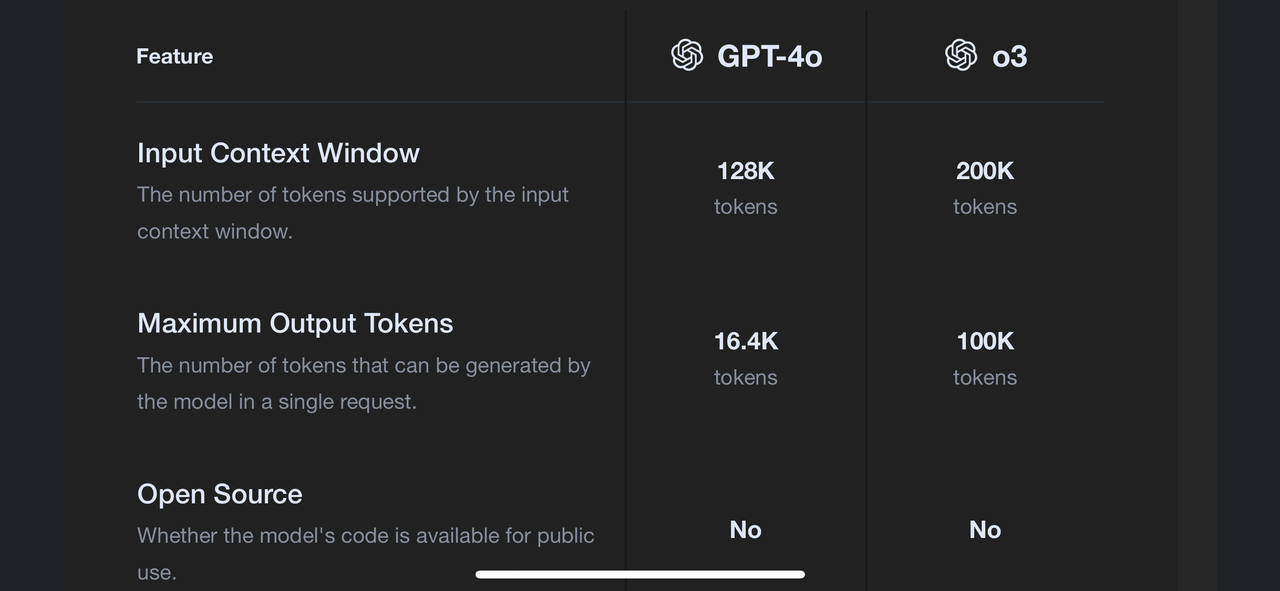
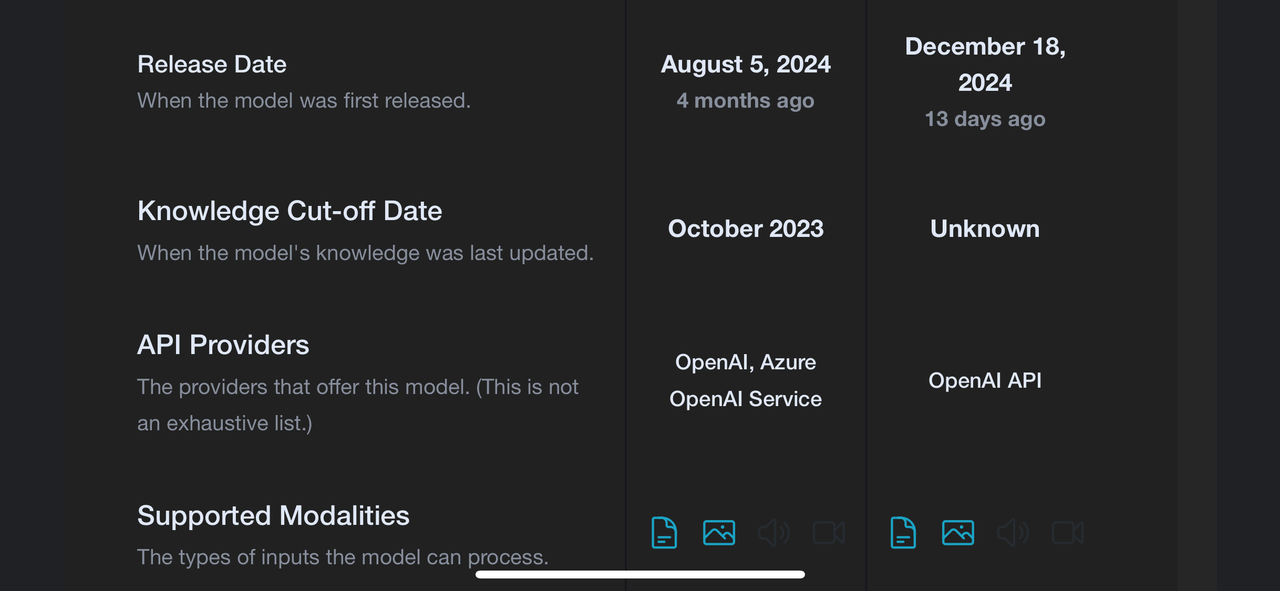
STEM版,合并数学,物理,化学,科学,工程,机械。不包括生物、医学相关,和计算机相关内容。
版主: verdelite , TheMatrix
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 10:33
上次由 TheMatrix 在 2025年 1月 1日 10:37 修改。
原因: 未提供修改原因
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 10:47
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 11:06
上次由 TheMatrix 在 2025年 1月 1日 11:07 修改。
原因: 未提供修改原因
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 11:09
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 11:19
TheMatrix 写了: 2025年 1月 1日 11:09
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
这个路线和ChatGPT是合拍的。任何人用过ChatGPT一段时间就会发现,ChatGPT需要ask the right question。一小步一小步的问,还需要refine questions,这样才能得到更好的答案。问题分解里有很多机械的步骤,把它自动化起来,再加点AI assisted自动分解,对于现有的AI是一个小跳跃,但是效果很丰厚。
有下一步可走,这是好事。说明OpenAI还在正确的道路上。
x1
wass
论坛精英2024年度优秀版主 wass 的博客
帖子互动: 775 帖子: 7718 注册时间: 2022年 7月 23日 22:13
帖子
由 wass 2025年 1月 1日 11:30
好像就是reasoning
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 11:39
wass 写了: 2025年 1月 1日 11:30
好像就是reasoning
O1、O3就是干这个的
cot公开更好,至少openai不愿意
cot的idea不存在秘密,本身就是公开的。但是需要ChatGPT,没有ChatGPT,CoT也没有效果。
wass
论坛精英2024年度优秀版主 wass 的博客
帖子互动: 775 帖子: 7718 注册时间: 2022年 7月 23日 22:13
帖子
由 wass 2025年 1月 1日 11:46
TheMatrix 写了: 2025年 1月 1日 11:39
cot的idea不存在秘密,本身就是公开的。但是需要ChatGPT,没有ChatGPT,CoT也没有效果。
说的是reasoning steps不愿意公开
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 16:22
TheMatrix 写了: 2025年 1月 1日 11:09
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
CoT应该还是为了挖掘LLM已有的潜力,也就是CoT能得到的最好的回答,用人工prompt engineering也能得到。
我说的是目前的CoT。应该不能推理。
wildthing
著名点评
帖子互动: 278 帖子: 4551 注册时间: 2022年 7月 22日 14:25
帖子
由 wildthing 2025年 1月 1日 16:26
TheMatrix 写了: 2025年 1月 1日 16:22
CoT应该还是为了挖掘LLM已有的潜力,也就是CoT能得到的最好的回答,用人工prompt engineering也能得到。
我说的是目前的CoT。应该不能推理。
reinforcement learning model is difficult to train.
司马光在《资治通鉴》中说日本人:'知小礼而无大义,拘小节而无大德。重末节而无廉耻,畏威而不怀德。强必盗寇,弱必卑伏'。
康熙皇帝在《康熙朝起居注》中这样评论日本人:“倭子国,最是反复无常之国。其人,甚卑贱,不知世上有恩谊,只一味慑于武威……故尔,不得对其有稍许好颜色。”
FoxMe (令狐)
论坛精英
帖子互动: 157 帖子: 5577 注册时间: 2022年 7月 26日 16:46
帖子
由 FoxMe (令狐) 2025年 1月 1日 17:06
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 17:06
wildthing 写了: 2025年 1月 1日 16:26
reinforcement learning model is difficult to train.
reinforcement learning没有labeled数据,也就是没有正确答案。要用rewards and punishments来优化。它的难点在哪?
TheMatrix 楼主
论坛支柱2024年度优秀版主 TheMatrix 的博客
帖子互动: 278 帖子: 13646 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix 楼主 2025年 1月 1日 17:07
FoxMe 写了: 2025年 1月 1日 17:06 token是啥?
token可以理解为单词。
ChatGPT不是一个单词一个单词往外蹦吗?这就是token。
wildthing
著名点评
帖子互动: 278 帖子: 4551 注册时间: 2022年 7月 22日 14:25
帖子
由 wildthing 2025年 1月 1日 17:11
TheMatrix 写了: 2025年 1月 1日 17:06
reinforcement learning没有labeled数据,也就是没有正确答案。要用rewards and punishments来优化。它的难点在哪?
no local extrema. It is a saddle point and very unstable. You can't determine the stopping criterion using training losses.
司马光在《资治通鉴》中说日本人:'知小礼而无大义,拘小节而无大德。重末节而无廉耻,畏威而不怀德。强必盗寇,弱必卑伏'。
康熙皇帝在《康熙朝起居注》中这样评论日本人:“倭子国,最是反复无常之国。其人,甚卑贱,不知世上有恩谊,只一味慑于武威……故尔,不得对其有稍许好颜色。”