分页: 1 / 1
#1 ChatGPT 4o vs o3
发表于 : 2025年 1月 1日 10:33
由 TheMatrix
#2 Re: ChatGPT 4o vs o3
发表于 : 2025年 1月 1日 10:47
由 TheMatrix
#1 CoT - chain of thought
发表于 : 2025年 1月 1日 11:06
由 TheMatrix
#2 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 11:09
由 TheMatrix
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
#3 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 11:19
由 TheMatrix
TheMatrix 写了: 2025年 1月 1日 11:09
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
这个路线和ChatGPT是合拍的。任何人用过ChatGPT一段时间就会发现,ChatGPT需要ask the right question。一小步一小步的问,还需要refine questions,这样才能得到更好的答案。问题分解里有很多机械的步骤,把它自动化起来,再加点AI assisted自动分解,对于现有的AI是一个小跳跃,但是效果很丰厚。
有下一步可走,这是好事。说明OpenAI还在正确的道路上。
#4 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 11:30
由 wass
好像就是reasoning
O1、O3就是干这个的
cot公开更好,至少openai不愿意
#5 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 11:39
由 TheMatrix
wass 写了: 2025年 1月 1日 11:30
好像就是reasoning
O1、O3就是干这个的
cot公开更好,至少openai不愿意
cot的idea不存在秘密,本身就是公开的。但是需要ChatGPT,没有ChatGPT,CoT也没有效果。
#6 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 11:46
由 wass
TheMatrix 写了: 2025年 1月 1日 11:39
cot的idea不存在秘密,本身就是公开的。但是需要ChatGPT,没有ChatGPT,CoT也没有效果。
说的是reasoning steps不愿意公开
#3 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 16:22
由 TheMatrix
TheMatrix 写了: 2025年 1月 1日 11:09
CoT - chain of thought 就是prompt engineering。原来是人来做的,现在希望AI自己做。
CoT应该还是为了挖掘LLM已有的潜力,也就是CoT能得到的最好的回答,用人工prompt engineering也能得到。
我说的是目前的CoT。应该不能推理。
#4 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 16:26
由 wildthing
TheMatrix 写了: 2025年 1月 1日 16:22
CoT应该还是为了挖掘LLM已有的潜力,也就是CoT能得到的最好的回答,用人工prompt engineering也能得到。
我说的是目前的CoT。应该不能推理。
reinforcement learning model is difficult to train.
#5 Re: ChatGPT 4o vs o3
发表于 : 2025年 1月 1日 17:06
由 FoxMe
#6 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 17:06
由 TheMatrix
wildthing 写了: 2025年 1月 1日 16:26
reinforcement learning model is difficult to train.
reinforcement learning没有labeled数据,也就是没有正确答案。要用rewards and punishments来优化。它的难点在哪?
#7 Re: ChatGPT 4o vs o3
发表于 : 2025年 1月 1日 17:07
由 TheMatrix
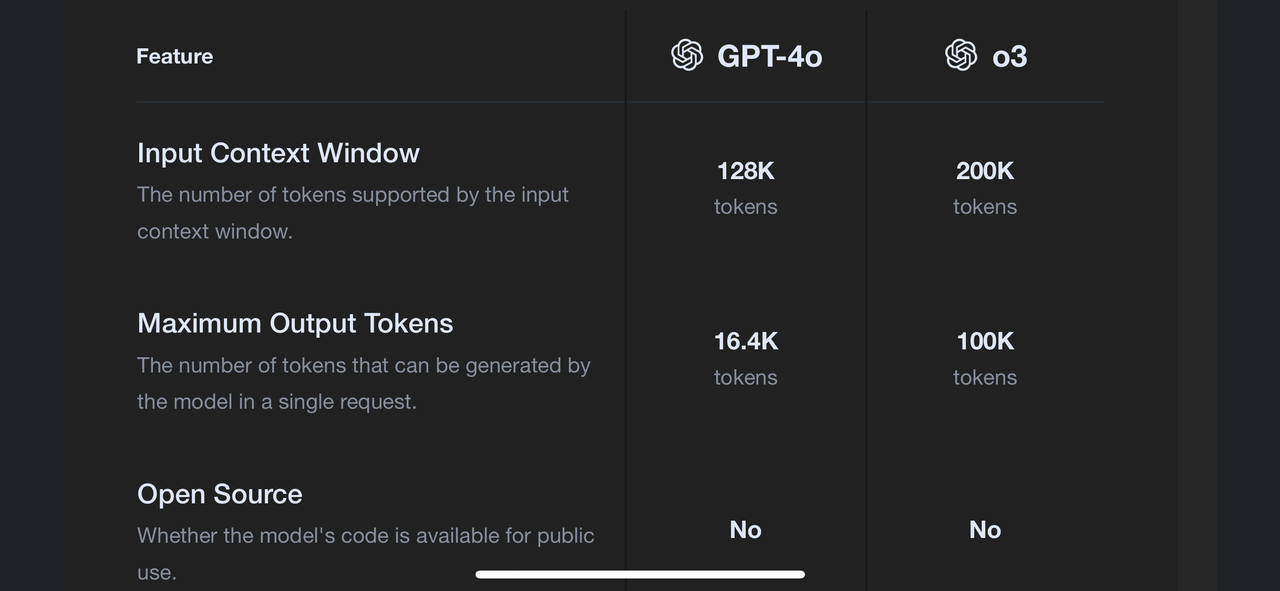
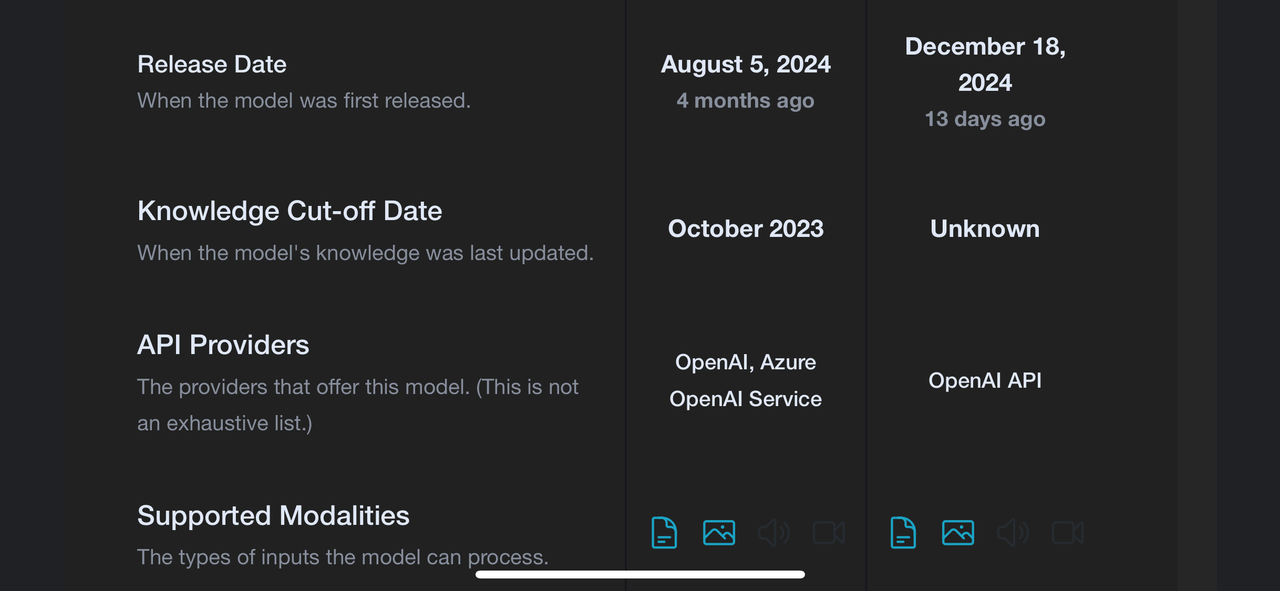
FoxMe 写了: 2025年 1月 1日 17:06token是啥?
token可以理解为单词。
ChatGPT不是一个单词一个单词往外蹦吗?这就是token。
#8 Re: CoT - chain of thought
发表于 : 2025年 1月 1日 17:11
由 wildthing
TheMatrix 写了: 2025年 1月 1日 17:06
reinforcement learning没有labeled数据,也就是没有正确答案。要用rewards and punishments来优化。它的难点在哪?
no local extrema. It is a saddle point and very unstable. You can't determine the stopping criterion using training losses.